Abstract
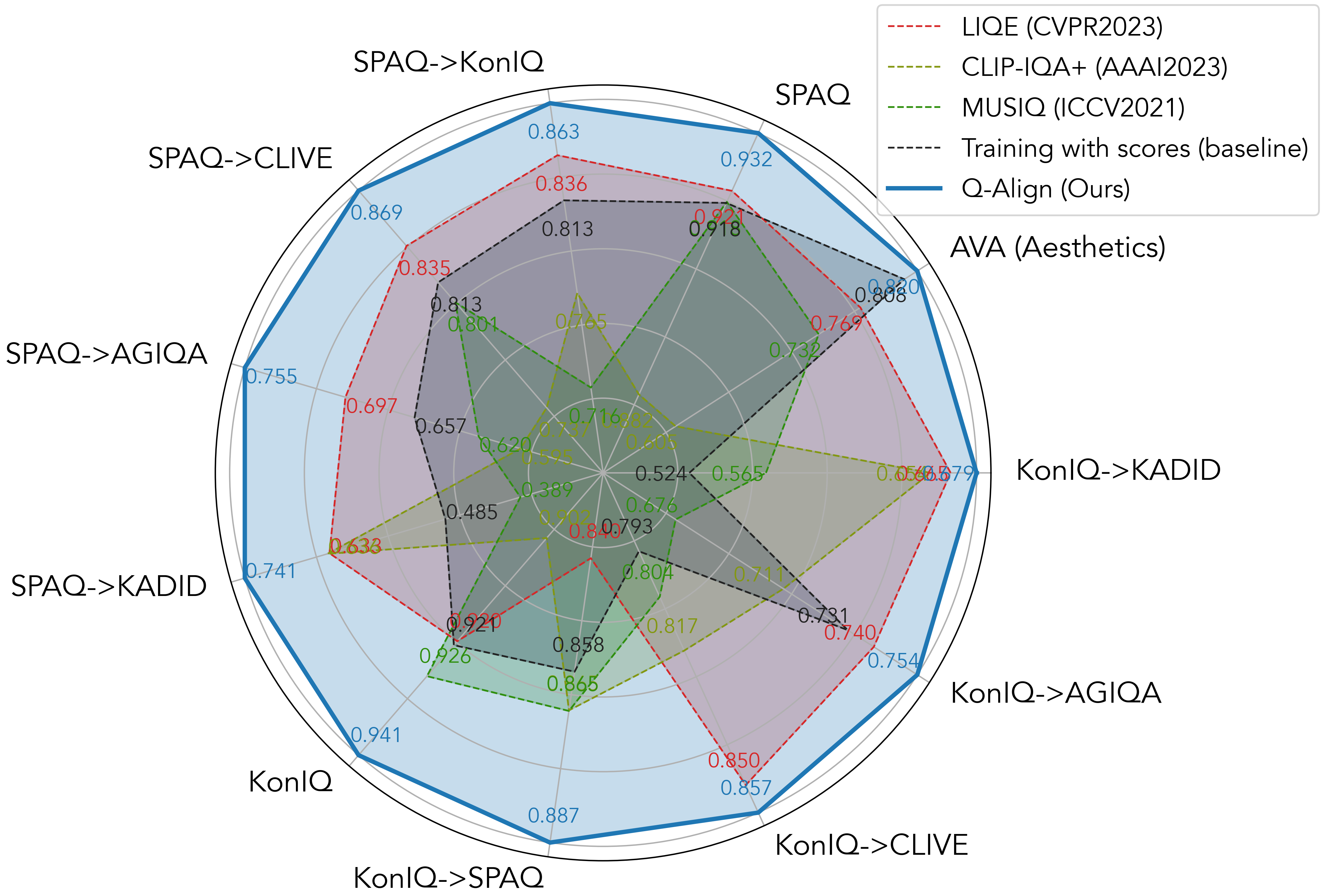
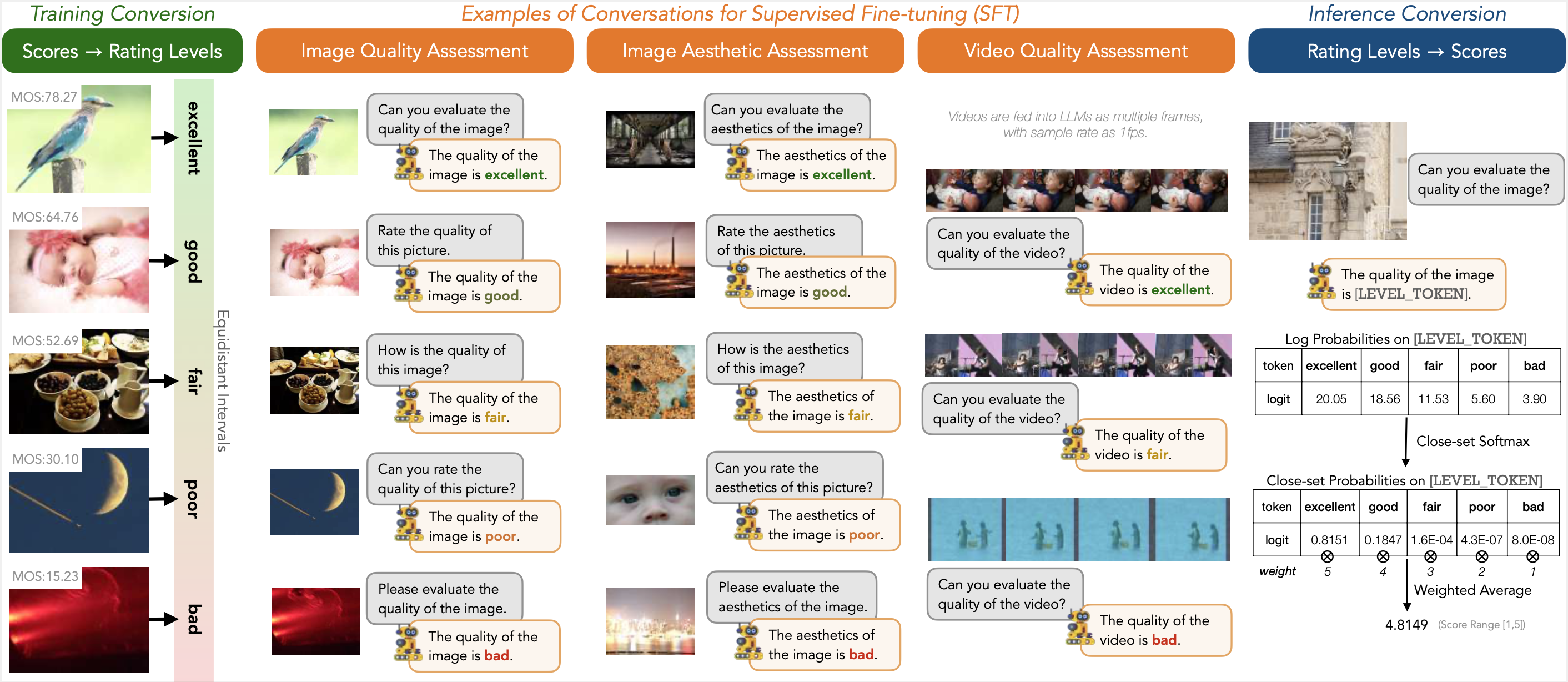
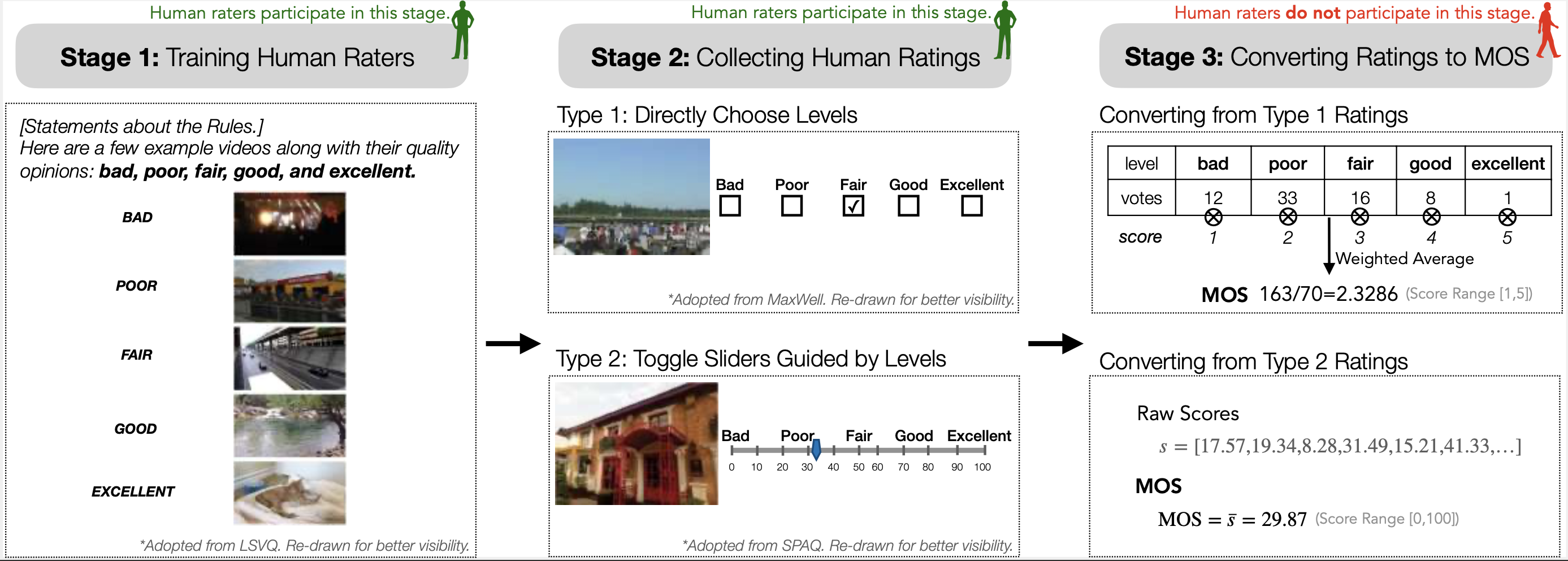
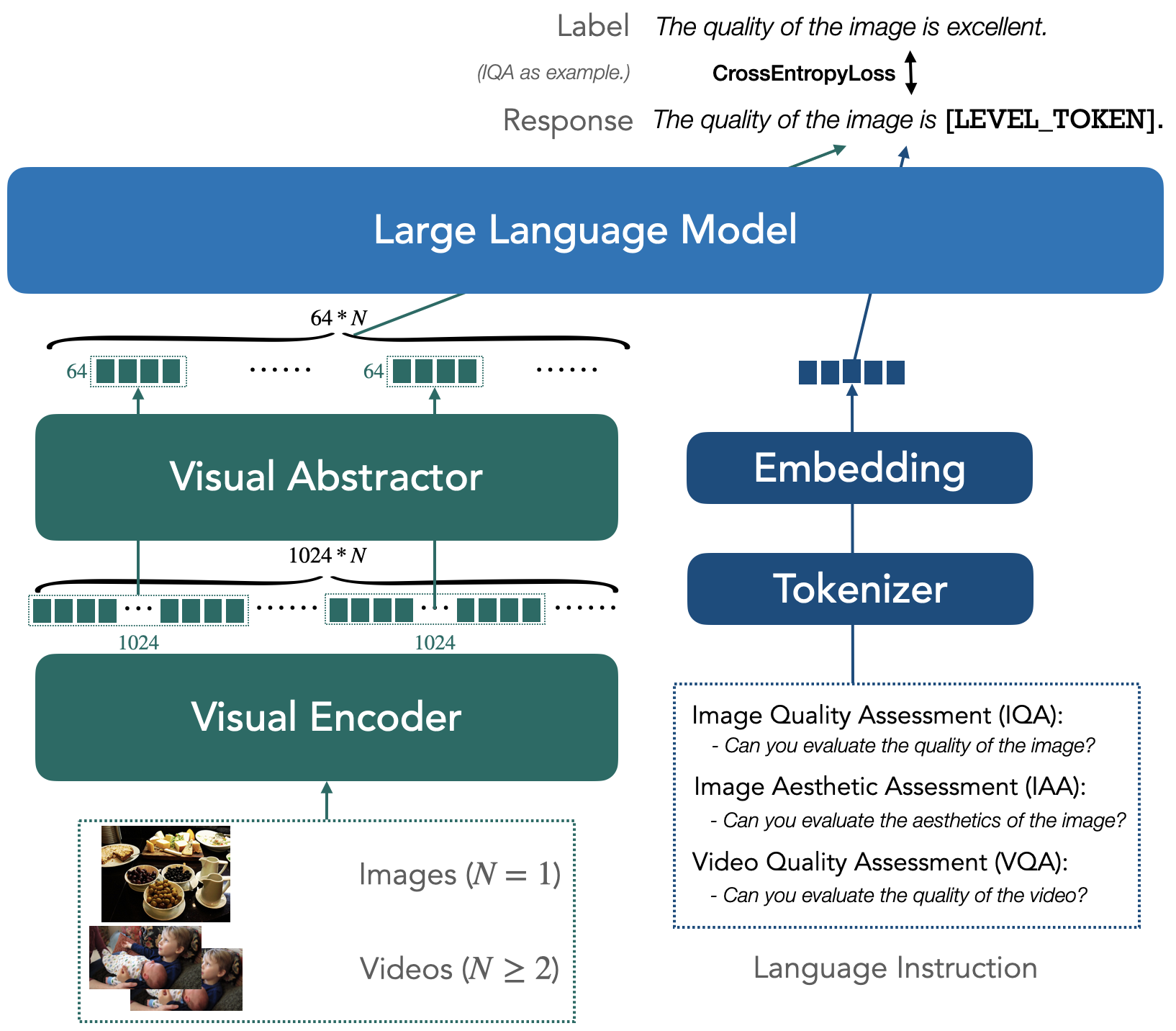
The explosion of visual content available online underscores the requirement for an accurate machine assessor to robustly evaluate scores across diverse types of visual contents. While recent studies have demonstrated the exceptional potentials of large multi-modality models (LMMs) on a wide range of related fields, in this work, we explore how to teach them for visual rating aligned with human opinions. Observing that human raters only learn and judge discrete text-defined levels in subjective studies, we propose to emulate this subjective process and teach LMMs with text-defined rating levels instead of scores. The proposed Q-Align achieves state-of-the-art performance on image quality assessment (IQA), image aesthetic assessment (IAA), as well as video quality assessment (VQA) tasks under the original LMM structure. With the syllabus, we further unify the three tasks into one model, termed the OneAlign. In our experiments, we demonstrate the advantage of the discrete-level-based syllabus over direct-score-based variants for LMMs.